Anatomy of the Unreal 4 blueprint virtual machine#
Translated from this excellent series https://www.cnblogs.com/ghl_carmack/p/6060383.html
Foreword#
Here, we intend to give a general explanation of the implementation of the blueprint virtual machine in Unreal 4. If you have a clear understanding of other scripting language implementations, it will be much easier to understand. We will first briefly introduce related terms , And then explain the implementation of the blueprint virtual machine.
Terminology#
Programming languages are generally divided into compiled languages and interpreted languages.
Compiled Language#
Before the program is executed, a special compilation process is needed to compile the program into a file in machine language. It does not need to be re-translated at runtime, and the compiled results are used directly. Program execution efficiency is high, it depends on the compiler, and cross-platform performance is poor. Such as C, C ++, Delphi, etc.
Interpreted Language#
The program is written without precompilation, and the program code is stored as text. When publishing the program, it seemed that the compilation process was saved. However, when running a program, the interpreted language must be interpreted before running.
However, whether Java, C #, etc. are interpreted languages is controversial, because their mainstream implementations are not directly interpreted and executed, but are also compiled into bytecode and then run on virtual machines such as jvm.
The implementation of the blueprint in UE4 is more like the implementation of Lua. It cannot be run independently, but as an extended script embedded in the host language. Lua can be directly interpreted and executed, or it can be compiled into bytecode and saved to disk. On the next call, you can directly load the compiled bytecode for execution.
What is a virtual machine#
Virtual machines were originally defined by Popek [a] and Goldberg as valid, independent copies of real machines. Currently includes virtual machines that have nothing to do with any real machine. Virtual machines are divided into two categories based on their use and relevance to direct machines. System virtual machines (such as VirtualBox) provide a complete system platform that can run a complete operating system. In contrast, a program virtual machine (such as the Java JVM) is designed to run a single computer program, which means that it supports a single process. An essential feature of a virtual machine is that the software running on the virtual machine is limited to the resources provided by the virtual machine-it cannot exceed the virtual world.
Here we are mainly concerned with the program virtual machine. Since the VM is called a "machine", the input is generally considered to be an instruction sequence that meets an instruction set architecture (ISA). If executed, the output is the execution result of the program, which is the VM. The source and target ISA can be the same, this is the so-called same-ISA VM.
Classification#
Virtual machine implementation is divided into register-based virtual machines and stack-based virtual machines.
Three-address instruction#
a = b + c;
If you turn it into this form:
add a, b, c
That looks more like machine instructions, right? This is the so-called "3-address instruction" and its general form is:
op dest, src1, src2
Many operations are binary operations + assignments. The three-address instruction can specify exactly two sources and one target, and can flexibly support the combination of binary operations and assignments. The main instruction set of the ARM processor is in the form of three addresses.
Two address instructions#
a + = b;
become:
add a, b
This is the so-called "two-address instruction", and its general form is:
op dest, src
To support binary operations, it can only target one of the sources at the same time. After the execution of add a, b above, the original value of a is destroyed, while the value of b remains unchanged. x86 series processors are in the form of two addresses.
One address instruction#
Obviously, the instruction set can be any "n address", n is a natural number. So what is the instruction set in the form of an address?
Imagine a sequence of instructions like this:
add 5
sub 3
This only specifies the source of the operation, what is the target? In general, the goal of this kind of operation is a special register called an "accumulator". All operations are completed by updating the state of the accumulator. Then the two instructions above are written in C:
C code Favorite code
acc + = 5;
acc-= 3;
It's just that acc is the "hidden" target. Accumulator-based architectures are relatively rare these days, and have prospered on very old machines for some time.
Zero address instruction#
What if n of "n address" is 0?
Look at this piece of Java bytecode:
Java bytecode code
iconst_1
iconst_2
iadd
istore_0
Note that the iadd (for integer addition) instruction has no parameters. Even the source cannot be specified. What is the use of the zero address instruction? ?
Zero address means that the source and destination are implicit parameters, and its implementation depends on a common data structure-yes, it is the stack. The above two instructions, iconst_1 and iconst_2, push integer constants 1, 2 to a place called an "evaluation stack" (also called an operand stack or an operand stack or an expression stack). . The iadd instruction pops 2 values from the top of the evaluation stack, adds the values, and pushes the result back to the top of the stack. The istore_0 instruction pops a value from the top of the evaluation stack and saves the value to the first position in the local variable area (slot 0).
The instruction set in the form of zero address is generally implemented through a "stack-based architecture". Please note that this stack refers to the "evaluation stack", not the system call stack (or system stack). Don't get confused. Some virtual machines implement the evaluation stack on the system call stack, but the two are not conceptually the same thing.
Because the source and destination of the instruction are implicit, the "density" of a zero-address instruction can be very high-more instructions can be placed in less space. Therefore, in a space-constrained environment, the zero address instruction is a desirable design. But the zero-address instruction has to accomplish one thing. Generally, there are many more instructions than the two-address or three-address instruction. The addition made by the above Java bytecode can be completed by using two x86 instructions:
mov eax, 1
add eax, 2
Difference between stack-based and register-based structures#
- The location where the temporary value is saved is different
* Stack-based: Stores temporary values on the evaluation stack.
* Register-based: Save temporary values in registers. - The volume occupied by the code is different
* Stack-based: Code is compact and small, but requires many code conditions
* Register-based: the code is relatively large, but requires less code conditions
Based on the "stack" in the stack refers to the "evaluation stack", the "evaluation stack" in the JVM is called the "operand stack".
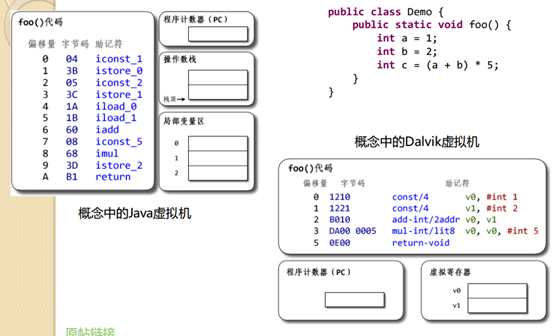
Stack frame#
A stack frame is also called a process activity record. It is a data structure used by the compiler to implement a procedure / function call. Logically, a stack frame is a function execution environment: function parameters, function local variables, where to return after the function is executed, and so on.
Blueprint virtual machine implementation#
Earlier we have briefly introduced the terms related to virtual machines. Next, we will specifically explain the implementation of the blueprint virtual machine in Unreal 4.
Byte code#
The bytecode of the virtual machine is in the Script.h file. Here we list it all. Because it is a dedicated scripting language, there will be some special bytecodes in it, such as proxy-related code (EX_BindDelegate, EX_AddMulticastDelegate). Of course, there are commonly used statements, such as assignment, unconditional jump instruction, conditional jump instruction, switch, etc.
//
// Evaluatable expression item types.
//
enum EExprToken
{
// Variable references.
EX_LocalVariable = 0x00, // A local variable.
EX_InstanceVariable = 0x01, // An object variable.
EX_DefaultVariable = 0x02, // Default variable for a class context.
// = 0x03,
EX_Return = 0x04, // Return from function.
// = 0x05,
EX_Jump = 0x06, // Goto a local address in code.
EX_JumpIfNot = 0x07, // Goto if not expression.
// = 0x08,
EX_Assert = 0x09, // Assertion.
// = 0x0A,
EX_Nothing = 0x0B, // No operation.
// = 0x0C,
// = 0x0D,
// = 0x0E,
EX_Let = 0x0F, // Assign an arbitrary size value to a variable.
// = 0x10,
// = 0x11,
EX_ClassContext = 0x12, // Class default object context.
EX_MetaCast = 0x13, // Metaclass cast.
EX_LetBool = 0x14, // Let boolean variable.
EX_EndParmValue = 0x15, // end of default value for optional function parameter
EX_EndFunctionParms = 0x16, // End of function call parameters.
EX_Self = 0x17, // Self object.
EX_Skip = 0x18, // Skippable expression.
EX_Context = 0x19, // Call a function through an object context.
EX_Context_FailSilent = 0x1A, // Call a function through an object context (can fail silently if the context is NULL; only generated for functions that don't have output or return values).
EX_VirtualFunction = 0x1B, // A function call with parameters.
EX_FinalFunction = 0x1C, // A prebound function call with parameters.
EX_IntConst = 0x1D, // Int constant.
EX_FloatConst = 0x1E, // Floating point constant.
EX_StringConst = 0x1F, // String constant.
EX_ObjectConst = 0x20, // An object constant.
EX_NameConst = 0x21, // A name constant.
EX_RotationConst = 0x22, // A rotation constant.
EX_VectorConst = 0x23, // A vector constant.
EX_ByteConst = 0x24, // A byte constant.
EX_IntZero = 0x25, // Zero.
EX_IntOne = 0x26, // One.
EX_True = 0x27, // Bool True.
EX_False = 0x28, // Bool False.
EX_TextConst = 0x29, // FText constant
EX_NoObject = 0x2A, // NoObject.
EX_TransformConst = 0x2B, // A transform constant
EX_IntConstByte = 0x2C, // Int constant that requires 1 byte.
EX_NoInterface = 0x2D, // A null interface (similar to EX_NoObject, but for interfaces)
EX_DynamicCast = 0x2E, // Safe dynamic class casting.
EX_StructConst = 0x2F, // An arbitrary UStruct constant
EX_EndStructConst = 0x30, // End of UStruct constant
EX_SetArray = 0x31, // Set the value of arbitrary array
EX_EndArray = 0x32,
// = 0x33,
EX_UnicodeStringConst = 0x34, // Unicode string constant.
EX_Int64Const = 0x35, // 64-bit integer constant.
EX_UInt64Const = 0x36, // 64-bit unsigned integer constant.
// = 0x37,
EX_PrimitiveCast = 0x38, // A casting operator for primitives which reads the type as the subsequent byte
// = 0x39,
// = 0x3A,
// = 0x3B,
// = 0x3C,
// = 0x3D,
// = 0x3E,
// = 0x3F,
// = 0x40,
// = 0x41,
EX_StructMemberContext = 0x42, // Context expression to address a property within a struct
EX_LetMulticastDelegate = 0x43, // Assignment to a multi-cast delegate
EX_LetDelegate = 0x44, // Assignment to a delegate
// = 0x45,
// = 0x46, // CST_ObjectToInterface
// = 0x47, // CST_ObjectToBool
EX_LocalOutVariable = 0x48, // local out (pass by reference) function parameter
// = 0x49, // CST_InterfaceToBool
EX_DeprecatedOp4A = 0x4A,
EX_InstanceDelegate = 0x4B, // const reference to a delegate or normal function object
EX_PushExecutionFlow = 0x4C, // push an address on to the execution flow stack for future execution when a EX_PopExecutionFlow is executed. Execution continues on normally and doesn't change to the pushed address.
EX_PopExecutionFlow = 0x4D, // continue execution at the last address previously pushed onto the execution flow stack.
EX_ComputedJump = 0x4E, // Goto a local address in code, specified by an integer value.
EX_PopExecutionFlowIfNot = 0x4F, // continue execution at the last address previously pushed onto the execution flow stack, if the condition is not true.
EX_Breakpoint = 0x50, // Breakpoint. Only observed in the editor, otherwise it behaves like EX_Nothing.
EX_InterfaceContext = 0x51, // Call a function through a native interface variable
EX_ObjToInterfaceCast = 0x52, // Converting an object reference to native interface variable
EX_EndOfScript = 0x53, // Last byte in script code
EX_CrossInterfaceCast = 0x54, // Converting an interface variable reference to native interface variable
EX_InterfaceToObjCast = 0x55, // Converting an interface variable reference to an object
// = 0x56,
// = 0x57,
// = 0x58,
// = 0x59,
EX_WireTracepoint = 0x5A, // Trace point. Only observed in the editor, otherwise it behaves like EX_Nothing.
EX_SkipOffsetConst = 0x5B, // A CodeSizeSkipOffset constant
EX_AddMulticastDelegate = 0x5C, // Adds a delegate to a multicast delegate's targets
EX_ClearMulticastDelegate = 0x5D, // Clears all delegates in a multicast target
EX_Tracepoint = 0x5E, // Trace point. Only observed in the editor, otherwise it behaves like EX_Nothing.
EX_LetObj = 0x5F, // assign to any object ref pointer
EX_LetWeakObjPtr = 0x60, // assign to a weak object pointer
EX_BindDelegate = 0x61, // bind object and name to delegate
EX_RemoveMulticastDelegate = 0x62, // Remove a delegate from a multicast delegate's targets
EX_CallMulticastDelegate = 0x63, // Call multicast delegate
EX_LetValueOnPersistentFrame = 0x64,
EX_ArrayConst = 0x65,
EX_EndArrayConst = 0x66,
EX_AssetConst = 0x67,
EX_CallMath = 0x68, // static pure function from on local call space
EX_SwitchValue = 0x69,
EX_InstrumentationEvent = 0x6A, // Instrumentation event
EX_ArrayGetByRef = 0x6B,
EX_Max = 0x100,
};
Stack Frame Details#
In Stack.h we can find the definition of FFrame. Although it defines a structure, the logic to execute the current code is encapsulated in it. Let's take a look at its data members:
// Variables.
UFunction* Node;
UObject* Object;
uint8* Code;
uint8* Locals;
UProperty* MostRecentProperty;
uint8* MostRecentPropertyAddress;
/** The execution flow stack for compiled Kismet code */
FlowStackType FlowStack;
/** Previous frame on the stack */
FFrame* PreviousFrame;
/** contains information on any out parameters */
FOutParmRec* OutParms;
/** If a class is compiled in then this is set to the property chain for compiled-in functions. In that case, we follow the links to setup the args instead of executing by code. */
UField* PropertyChainForCompiledIn;
/** Currently executed native function */
UFunction* CurrentNativeFunction;
bool bArrayContextFailed;
We can see that it saves the currently executing script function, the UObject that executes the script, the current code execution location, local variables, the previous stack frame, the parameters returned by the call (not the return value), and the currently executing native function Wait. The return value of the calling function is saved before the function call, and restored after the call ends. It looks like this:
uint8 * SaveCode = Stack.Code;
// Call function
...
Stack.Code = SaveCode
Below we list the important functions related to execution in FFrame:
// Functions.
COREUOBJECT_API void Step( UObject* Context, RESULT_DECL );
/** Replacement for Step that uses an explicitly specified property to unpack arguments **/
COREUOBJECT_API void StepExplicitProperty(void*const Result, UProperty* Property);
/** Replacement for Step that checks the for byte code, and if none exists, then PropertyChainForCompiledIn is used. Also, makes an effort to verify that the params are in the correct order and the types are compatible. **/
template<class TProperty>
FORCEINLINE_DEBUGGABLE void StepCompiledIn(void*const Result);
/** Replacement for Step that checks the for byte code, and if none exists, then PropertyChainForCompiledIn is used. Also, makes an effort to verify that the params are in the correct order and the types are compatible. **/
template<class TProperty, typename TNativeType>
FORCEINLINE_DEBUGGABLE TNativeType& StepCompiledInRef(void*const TemporaryBuffer);
COREUOBJECT_API virtual void Serialize( const TCHAR* V, ELogVerbosity::Type Verbosity, const class FName& Category ) override;
COREUOBJECT_API static void KismetExecutionMessage(const TCHAR* Message, ELogVerbosity::Type Verbosity, FName WarningId = FName());
/** Returns the current script op code */
const uint8 PeekCode() const { return *Code; }
/** Skips over the number of op codes specified by NumOps */
void SkipCode(const int32 NumOps) { Code += NumOps; }
template<typename TNumericType>
TNumericType ReadInt();
float ReadFloat();
FName ReadName();
UObject* ReadObject();
int32 ReadWord();
UProperty* ReadProperty();
/** May return null */
UProperty* ReadPropertyUnchecked();
/**
* Reads a value from the bytestream, which represents the number of bytes to advance
* the code pointer for certain expressions.
*
* @param ExpressionField receives a pointer to the field representing the expression; used by various execs
* to drive VM logic
*/
CodeSkipSizeType ReadCodeSkipCount();
/**
* Reads a value from the bytestream which represents the number of bytes that should be zero'd out if a NULL context
* is encountered
*
* @param ExpressionField receives a pointer to the field representing the expression; used by various execs
* to drive VM logic
*/
VariableSizeType ReadVariableSize(UProperty** ExpressionField);
Functions like ReadInt (), ReadFloat (), ReadObject (), and so on, we know what it does by seeing its name. It reads the corresponding int, float, UObject, etc. Here we mainly talk about the Step () function, and its code is as follows:
void FFrame::Step(UObject *Context, RESULT_DECL)
{
int32 B = *Code++;
(Context->*GNatives[B])(*this,RESULT_PARAM);
}
It can be seen that its main function is to fetch instructions and then find the corresponding function in the native function array to execute.
Byte code corresponding functions#
Earlier we listed all the bytecodes of all the virtual machines, then where is the code that corresponds to the specific execution part of each bytecode, you can find the definition in ScriptCore.cpp, we can see each bytecode The corresponding native functions are in GNatives and GCasts:
Their declarations are as follows:
/** The type of a native function callable by script */
typedef void (UObject::*Native)( FFrame& TheStack, RESULT_DECL );
Native GCasts[];
Native GNatives[EX_Max];
In this way, it will call the registration method for each native function, implemented through the IMPLEMENT_VM_FUNCTION and IMPLEMENT_CAST_FUNCTION macros.
The specific code is shown in the following figure:
#define IMPLEMENT_FUNCTION(cls,func) \
static FNativeFunctionRegistrar cls##func##Registar(cls::StaticClass(),#func,(Native)&cls::func);
#define IMPLEMENT_CAST_FUNCTION(cls, CastIndex, func) \
IMPLEMENT_FUNCTION(cls, func); \
static uint8 cls##func##CastTemp = GRegisterCast( CastIndex, (Native)&cls::func );
#define IMPLEMENT_VM_FUNCTION(BytecodeIndex, func) \
IMPLEMENT_FUNCTION(UObject, func) \
static uint8 UObject##func##BytecodeTemp = GRegisterNative( BytecodeIndex, (Native)&UObject::func );
It can be seen that it defines a global static object, so that the function will be placed in the corresponding position in the array before the main function of the program is executed, so that the corresponding native can be directly called when the virtual machine is executed. Function.
Implementation process#
When we talked about blueprints earlier, we talked about how blueprints interact with C ++, including blueprints calling C ++ code, and calling C ++ code into blueprints.
C ++ call blueprint function#
UFUNCTION(BlueprintImplementableEvent, Category = "AReflectionStudyGameMode")
void ImplementableFuncTest();
void AReflectionStudyGameMode::ImplementableFuncTest()
{
ProcessEvent(FindFunctionChecked(REFLECTIONSTUDY_ImplementableFuncTest),NULL);
}
Because our function has no parameters, a NULL is passed in all ProcessEvents. If there are parameters and return values, then UHT will automatically generate a structure for storing parameters and return values, so that when the function is called in C ++, It will go to the blueprint UFunction corresponding to the name REFLECTIONSTUDY_ImplementableFuncTest, and if it finds it, it will call ProcessEvent for further processing.
ProcessEvent process#
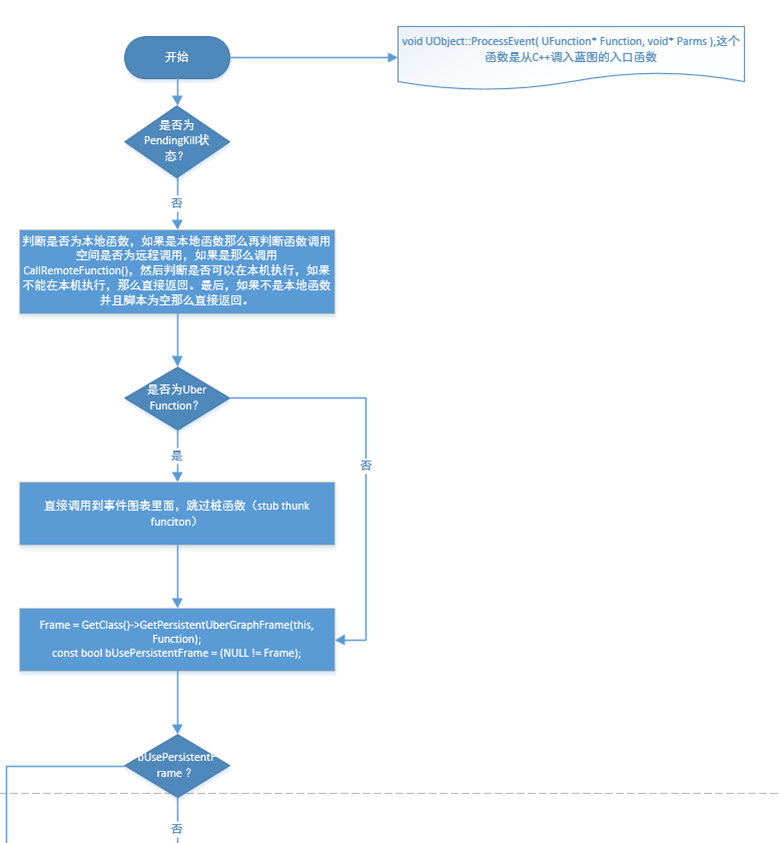
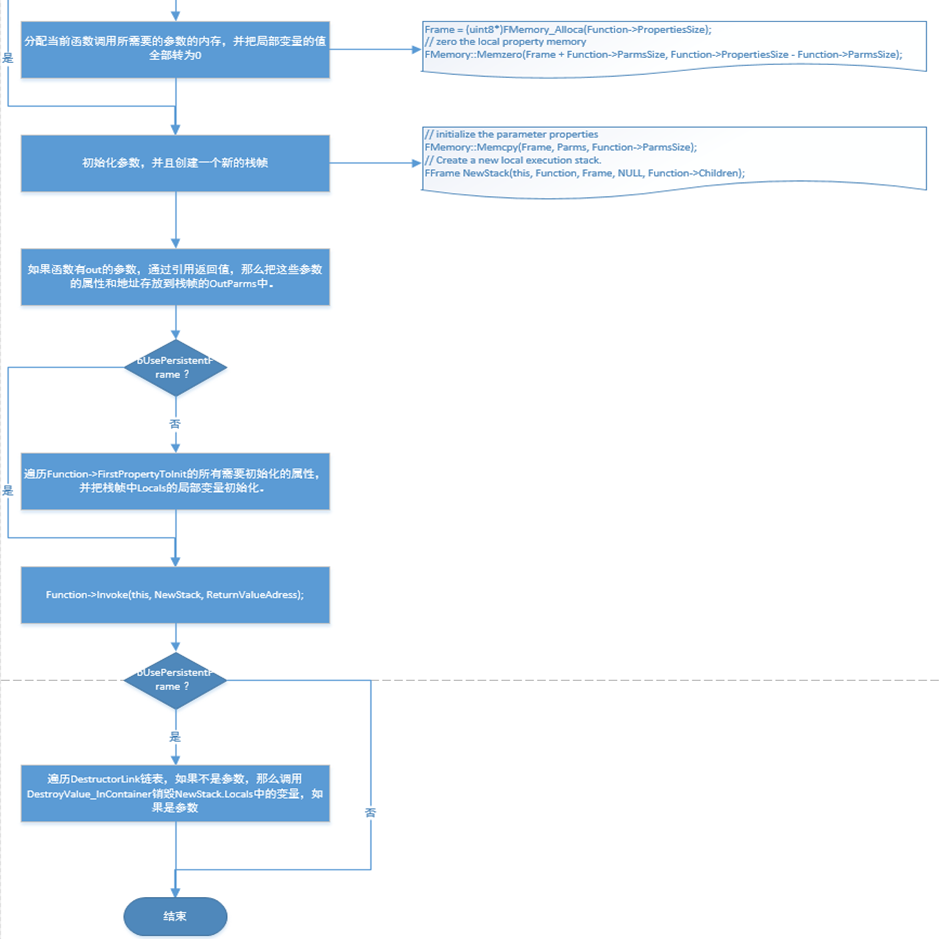
Blueprint calls C ++ functions#
UFUNCTION(BlueprintCallable, Category = "AReflectionStudyGameMode")
void CallableFuncTest();
DECLARE_FUNCTION(execCallableFuncTest) \
{ \
P_FINISH; \
P_NATIVE_BEGIN; \
this->CallableFuncTest(); \
P_NATIVE_END; \
}
If it is a C ++ function called through a blueprint, then UHT will generate the above code, and if there are parameters, it will call P_GET_UBOOL, etc. to obtain the corresponding parameters. If there is a return value, the return value will be assigned.
Summary#
At this point, plus our previous analysis of the blueprint compilation and the explanation of the blueprint virtual machine, we have a deeper understanding of the blueprint implementation principles. This article does not explain the predecessor of the blueprint, unrealscript in detail. With this in-depth understanding (if you want to have a deep understanding, you must look at the code yourself), I believe that everyone will be more at ease when designing the blueprint. Of course, if there is something wrong, please correct me, and everyone is welcome to discuss it. Next, we may focus on Unreal 4 rendering-related modules, including rendering API cross-platform related, multi-threaded rendering, rendering processes, and rendering algorithms, and some other modules may be interspersed (such as animation, AI, etc.) ), Everyone is welcome to continue to pay attention, if you have a chapter you want to know in advance, please also leave a comment below, I may make priority adjustments based on everyone's comments.
References: